Have you ever found yourself drowning in long documents—clinical notes, legal files, customer reviews, or even news articles—knowing there’s valuable information in there somewhere, but not having the time (or tools) to dig it out?
Manually combing through unstructured text is tedious, error-prone, and frankly, not scalable. Even using large language models (LLMs) without a thoughtful setup can lead to unpredictable or messy results.

What if you could tell an LLM exactly what you need, and it reliably gives you clean, structured answers—tied directly to their original source?
Google Gemini Deep Think Launched: A New Frontier in AI
Contents
Meet LangExtract: Your Smart Text Extraction Sidekick
LangExtract, is an open-source Python library that helps you extract meaningful data from messy text—quickly, reliably, and with full traceability. Whether you’re working with medical reports, financial data, or any large chunk of text, LangExtract helps you turn words into usable, structured information.
Powered by Google’s Gemini models (and compatible with other LLMs too), LangExtract is built to be lightweight, flexible, and developer-friendly.
Why LangExtract Stands Out
LangExtract combines thoughtful design with practical power. Here’s what makes it a game-changer:
Source-Linked Extra Precision
Every entity or data point it extracts is grounded—mapped right back to its original location in the source text. No guesswork. You can highlight and verify each extraction in context.
Structured Outputs You Can Trust
LangExtract doesn’t just spit out free-form text. You guide the model by providing an example or two (“few-shot learning”), and LangExtract uses that as a blueprint. With Controlled Generation (especially with Gemini), your outputs follow a predictable, structured schema.
Handles Long Documents with Ease
Long, dense documents? No problem. LangExtract breaks them into manageable chunks, processes them in parallel, and runs multiple extraction passes. This smart strategy helps maintain high accuracy—even when finding a ‘needle in a haystack.’
Interactive Visualizations in Minutes
Reviewing results has never been easier. LangExtract can turn your raw text and extracted data into an interactive HTML file—perfect for demos, evaluations, or just saving time. It works great in Google Colab or as a standalone HTML file.
Works with Your Favorite LLMs
Prefer Gemini? Great. Want to use an open-source model instead? Go ahead. LangExtract plays well with a variety of LLM backends.
Domain-Agnostic, Ready for Anything
Medical, legal, financial, engineering—you name it. With just a few solid examples, LangExtract can learn the structure you want and apply it across massive, unstructured datasets. No fine-tuning required.
Built-in World Knowledge (When You Want It)
LangExtract can optionally pull in world knowledge from the LLM—either from what’s explicitly in the text or inferred by the model. Just remember: the quality of this inferred knowledge depends heavily on the model and your example prompts.
Quick Demo: Extracting from Shakespeare
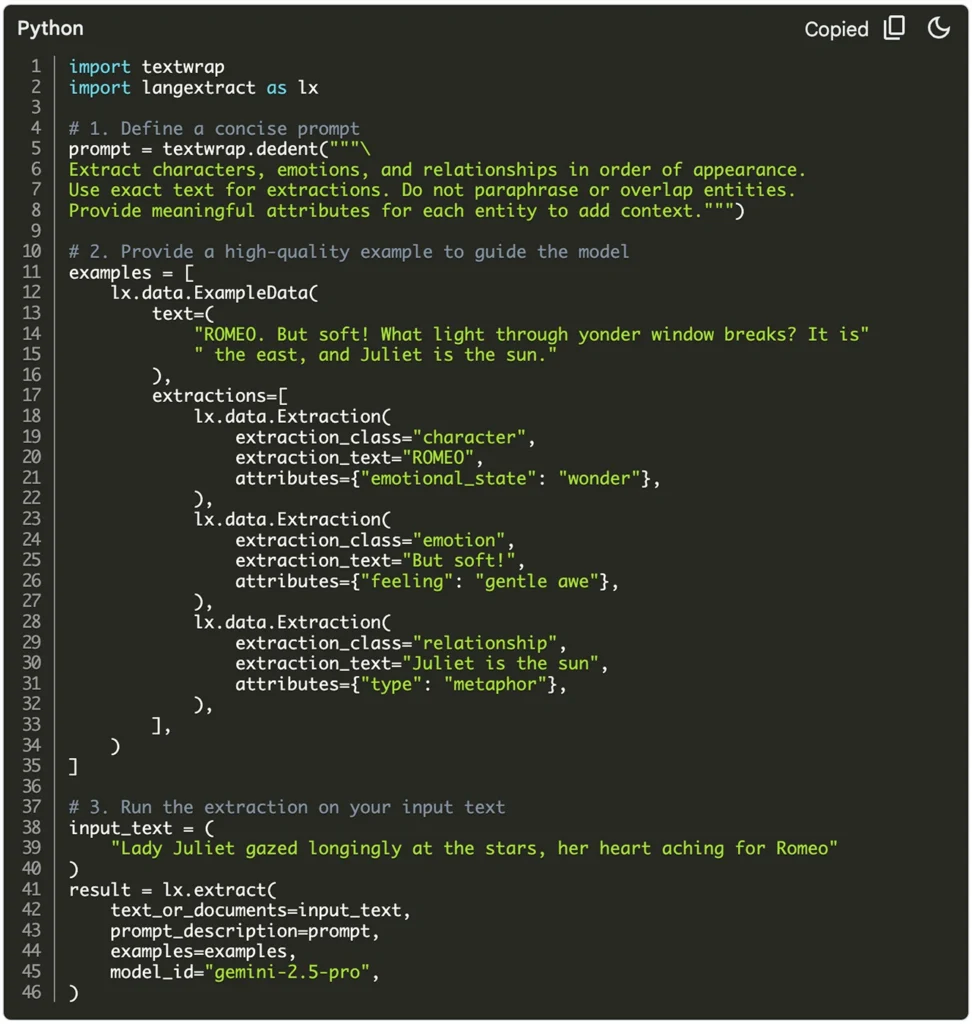
Let’s say you want to extract character details from a Shakespearean line. Here’s how simple it is to get started:
- Install the Library
pip install langextract - Define Your Task
Write a prompt and provide a high-quality example using theExampleDataandExtractionobjects. - Run the Extraction
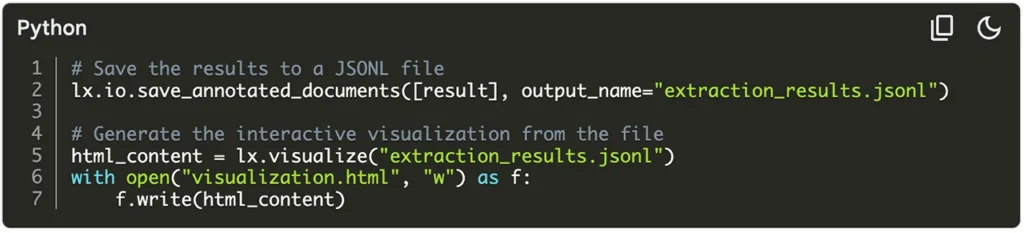
Use thelx.extract()function and pass in your text, example, prompt, and preferred model (e.g.,"gemini-2.5-pro"). - Visualize and Share
Save your results as JSONL, and generate an interactive HTML file usinglx.visualize.
Built for Specialized Use Cases Too
While LangExtract is great for general text, it truly shines in high-stakes fields like healthcare, finance, and law.
In fact, LangExtract’s roots are in medical information extraction—processing clinical notes to identify medications, dosages, and relationships between them.
To show off its potential, we also built RadExtract, a live demo for structured radiology reporting. Hosted on Hugging Face, it takes a free-text radiology report and transforms it into a clear, structured summary—highlighting the key findings for easier analysis and improved interoperability.
⚠️ Note: These examples are for demo purposes only. They’re not approved medical tools and should not be used for real-world diagnosis or treatment.
Ready to Try It?
Let’s see what we could build with LangExtract.
Head over to the GitHub repo, check out the full documentation, and start turning unstructured text into structured gold.