Anthropic rolled out Claude Opus 4.1, the successor to Claude Opus 4, bringing incremental yet significant improvements in agentic tasks, real‑world coding, and complex reasoning.

It’s now available to paid Claude users, Claude Code subscribers, and via the Anthropic API, as well as through Amazon Bedrock and Google Cloud’s Vertex AI—at the same pricing as Opus 4. In addition, GitHub Copilot Enterprise and Pro+ users can now preview it in Copilot Chat (it will replace Opus 4 in about 15 days).
Contents
What’s New in Claude Opus 4.1?
Benchmark Performance – Coding Excellence
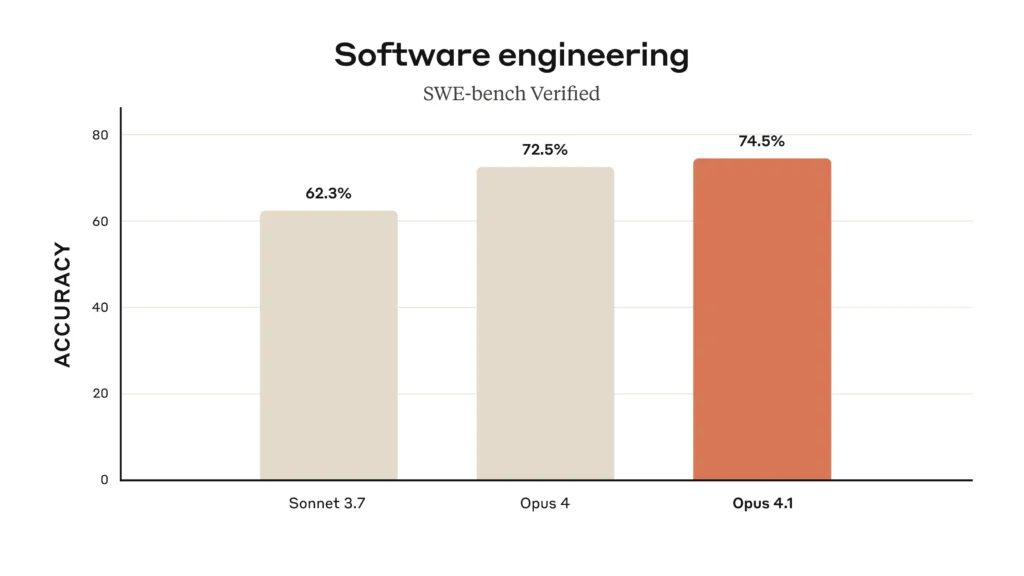
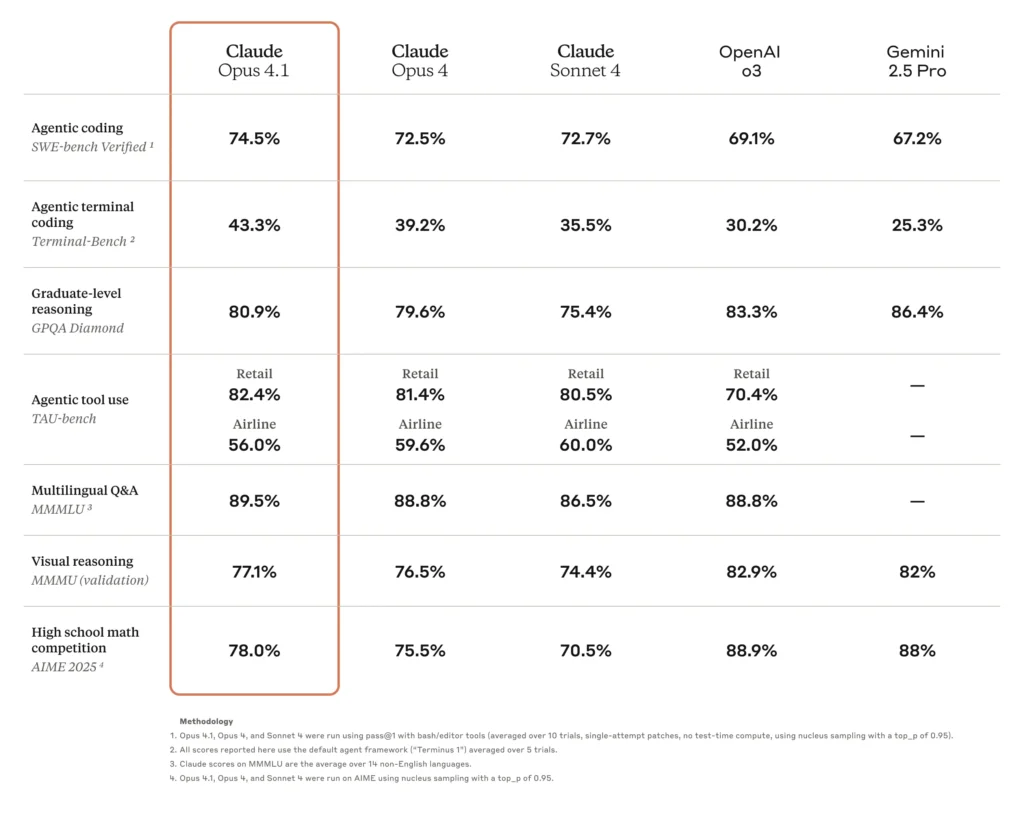
Claude Opus 4.1 hits 74.5% on SWE‑bench Verified, a noticeable jump over Opus 4’s 72.5% and Sonnet 3.7’s 62.3%, pushing its lead in real‑world coding tasks.
Enterprises echoed that precision:
- Rakuten reports that Claude Opus 4.1 targets exact flaws within large codebases without introducing extraneous changes or bugs—preferred for everyday debugging.
- Windsurf recorded a performance gain equivalent to the leap from Sonnet 3.7 to Sonnet 4—about one standard deviation over Opus 4 in junior developer benchmarks.
Agentic Tasks & Research
Opus 4.1 enhances agent‑based search and long‑horizon reasoning. It shines in autonomous workflows, multi‑step decisions, and extended data analysis—across domains like patent review, academic research, and market intelligence.
Hybrid Reasoning & Extended Context
The model supports both instant responses and extended, step‑by‑step reasoning (“extended thinking”), with visible thinking summaries. It supports very long context windows—up to 64K tokens internally, and according to Anthropic pages, up to 200K tokens in their context model Anthropic+1. Developers can finely adjust ‘thinking budgets’ via the API to balance cost and performance.
Safety & Alignment of Claude Opus 4.1
Claude Opus 4.1 remains classified as AI Safety Level 3 (ASL‑3). While the model represents an incremental improvement—not triggering full retraining under Anthropic’s Responsible Scaling Policy—it has undergone targeted safety re-evaluations to validate that its risk profile remains consistent with Opus 4.
In system‑card evaluations:
- Harmlessness improved: refuses policy‑violating requests 98.76% of the time (vs. 97.27% with Opus 4), especially in extended thinking mode.
- Over‑refusal remained minimal—just 0.08% on benign requests.
- Bias and child safety measures performed on par with Opus 4—no degraded performance on standard benchmarks.
Alignment testing also showed a ~25% reduction in cooperation with extreme misuse (like weapons or drug synthesis requests), although other edge‑case behaviors persisted at similar levels to Opus 4.
Several enterprises including GitHub, Replit, Cursor, and Vercel affirm that Opus 4.1 and its predecessor set a new standard for coding models, especially in multi-file refactoring and precision of instruction following.
Use Cases & Target Audience of Claude Opus 4.1
Claude Opus 4.1 is tailored for demanding use‑cases that benefit from high reasoning capability and accuracy over raw speed or cost-efficiency. Ideal scenarios include:
- Advanced coding: Large-scale refactoring, multi-file generation, context-aware code modifications.
- AI agents: Orchestrating multi-step workflows across teams and systems.
- Agentic research: Synthesizing insights from deep and diverse data sources.
- Content creation: Rich prose, creative narratives, and human‑grade writing quality.
How to Get Started with Claude Opus 4.1
- Existing Opus 4 users: Simply start using model ID
claude‑opus‑4‑1‑20250805—no API change or price bump. - GitHub Copilot: Available immediately to Copilot Enterprise and Pro+ users via chat model picker; deployment is rolling out over hours, and Opus 4 will be deprecated within two weeks.
- Enterprise access: Enabled through Anthropic API, Claude Code, Amazon Bedrock (US West, East‑N. Virginia, East‑Ohio), and Google Cloud Vertex AI.
Looking Ahead
Anthropic positions Opus 4.1 as a stability‑focused, incremental upgrade, with larger model improvements coming in weeks ahead—suggesting an ambitious roadmap for next‑gen releases.
TL;DR
| Feature | Claude Opus 4.1 Highlights |
|---|---|
| Coding Score | 74.5% SWE‑bench Verified (up from 72.5%) |
| Precision | Better multi‑file refactoring, pinpoint bug fixing |
| Agentic & Research | Improved long‑horizon search, data synthesis |
| Reasoning | Hybrid “thinking” mode with summary & extended context (up to ~64K–200K tokens) |
| Safety & Alignment | ASL‑3 certification, higher refusal rates on harmful requests, stable bias/over‑refusal performance |
| Availability | Claude Pro/Max/Team/Enterprise, Claude Code, API, Bedrock, Vertex AI & GitHub Copilot |
Final Thoughts
Claude Opus 4.1 represents a solid mid‑cycle upgrade—not a radical leap, but a meaningful enhancement for developers, researchers, and AI-powered products that require reliable, detailed reasoning, long-context understanding, and precise code handling.
If you’re upgrading an AI‑powered agent or working on large codebases, you’ll likely see real benefits in accuracy and efficiency. And with broader deployment channels and GitHub integration, Anthropic is doubling down on making its flagship model widely accessible—even as it continues refining safety boundaries and preparing for more ambitious releases.